Hace poco publiqué unas Reglas Mínimas de Buenas Prácticas de Programación, orientadas principalmente a las prácticas con el control de código fuente que estábamos haciendo.
En esta ocasión voy a tomar parte de lo escrito allí y a extenderme más sobre esas y algunas otras, de forma de tener una Guía más completa respecto de la programación en general con algunas cosas específicas de FoxPro y en algunos casos con el por qué o en qué beneficia hacerlo, ya que personalmente considero muy importante qué es lo que motiva a recomendar hacer las cosas de una forma determinada.
¿Qué son y para qué sirven las buenas prácticas?
Las buenas prácticas no existen desde siempre, sino que se fueron desarrollando como resultado de la experiencia común de muchos desarrolladores y empresas dedicadas al desarrollo de software, como Microsoft y otras.
En esas experiencias se han pasado muchas veces por situaciones conflictivas, que luego de haber identificado fallos o problemas comunes, y luego de haber analizado los motivos que llevaron a ellos, se han ido perfeccionando ciertas prácticas que minimizan la posibilidad de los mismos.
Otra ventaja de las buenas prácticas, es que tienden a facilitar el mantenimiento del código, no solo por la persona que lo hace, sino por otros, lo que permite "normalizar" la forma de hacer las cosas, bajar los tiempos de desarrollo y maximizar la eficiencia.
Finalmente, el uso de estas normas minimiza los problemas y las diferencias a la hora de tener que mezclar el código de dos desarrollos sobre los mismos componentes (llamado merge), aumentando la posibilidad de que sea automático y no requiera intervención manual.
1. Convención de nomenclatura de variables (VFP)
Está detallada en la ayuda de FoxPro y en el MSDN de Microsoft
Resumen:
- La primera letra define el alcance (local, privada, global)
- La segunda letra define el tipo de dato (numérico, carácter, date, etc)
- El nombre debe definir el concepto que representa
Ejemplos de nomenclatura:
Parámetros (t) => tcCadena, tnNumero, tdFecha, tlBoolean, taArray, toObjeto
Variables Locales (l) => lcCadena, lnNumero, ldFecha, llBoolean, laArray, loObjeto
Variables Privadas (p) => pcCadena, pnNumero, pdFecha, plBoolean, paArray, poObjeto
Variables Publicas (g) => gcCadena, gnNumero, gdFecha, glBoolean, gaArray, goObjeto
Ejemplos de buen uso conceptual:
ldFechaNacimiento
glUsuarioActivo
llActivateEjecutado
Beneficios:
- Permite distinguir rápidamente los distintos alcances y tipos de variables y propiedades, por lo que pueden convivir variables o propiedades del mismo nombre y distinto alcance o tipo (ej: gdFecha y ldFecha)
- Ayudan, en parte, a ver si un método está bien encapsulado o si requiere mayor parametrización. Como regla general, conviene usar siempre variables locales para mantener la encapsulación de la funcionalidad
- Impide que se confunda una variable con un nombre de campo (lcClave y clave)
- Ayuda a entender mejor el código y lo que hace
2. Convensión de nomenclatura de objetos (VFP)
Está detallada en la ayuda de FoxPro y en el MSDN de Microsoft
Resumen:
- Las primeras 3 letras definen el tipo de objeto
- El nombre debe definir funcionalmente para qué sirve
Ejemplos de nomenclatura:
custom => cus_nombre
label => lbl_nombre
form => frm_nombre
checkbox => chk_nombre
editbox => edt_nombre
listbox => lst_nombre
spinner => spn_nombre
pageFrame => pgf_Nombre
page => pag_Nombre
commandButton => cmd_nombre
custom => cus_nombre
label => lbl_nombre
form => frm_nombre
checkbox => chk_nombre
editbox => edt_nombre
listbox => lst_nombre
spinner => spn_nombre
pageFrame => pgf_Nombre
page => pag_Nombre
commandButton => cmd_nombre
Ejemplos de buen uso conceptual:
txt_FechaDeNacimiento
cmd_CerrarFormulario
pag_ConfiguracionesDeUsuario
frm_PermisosPorUsuarioYGrupo
txt_FechaDeNacimiento
cmd_CerrarFormulario
pag_ConfiguracionesDeUsuario
frm_PermisosPorUsuarioYGrupo
Beneficios:
- Permite distinguir rápidamente los distintos tipos de objetos
- Ayuda a entender mejor el código y lo que hace
3. Checkin y checkout de componentes (SCM/VFP)
Recomendación:
Antes de hacer un checkin o un checkout de componentes, es conveniente limpiar el entorno para evitar problemas:
CLEAR ALL
CLOSE ALL
o incluso cerrar la sesión de VFP si se usa para ejecutar, y luego ya se puede hacer el checkin o checkout.
Beneficios:
- Evitar errores por "archivo en uso"
- Evitar hacer checkin de partes del componente (proteger SCX sin su SCT, etc) si el SCM no usa transacciones atómicas (todo o nada)
4. Sesiones de FoxPro
Recomendación:
- Evitar cambiar el directorio de una sesión de FoxPro que sea usada para modificar componentes, o sea, no usar CD <directorio> o SET DEFAULT TO <directorio> si se modifican programas con MODIFY o se ejecutan con DO.
- Para distintos sistemas o programas en distintos directorios, es mejor usar sesiones independientes de VFP (o sea, abrir un VFP para cada sistema)
Beneficios:
- FoxPro suele cachear los programas y clases en la memoria, y al modificar en otra ubicación se podrían guardar rutas inválidas o apuntando a otro directorio, sobre todo en las clases y forms
- Usando sesiones de FoxPro independientes, se puede editar en una y ejecutar en otra, y si algo sale mal durante la ejecución y hay que matar esa sesión, la edición y el proyecto se mantienen sin cambios en la otra sesión y se evita que se corrompan los archivos
5. Recepción de Parámetros en métodos
Recomendaciones:
- Usar LPARAMETERS en vez de PARAMETERS y si hay que agregar parámetros a un método, agregarlos siempre al final, nunca en medio o al inicio de los parámetros existentes.
- Usar PCOUNT() en vez de PARAMETERS()
Ejemplo agregando nuevo parámetro "tnCosto":
LPARAMETERS tcNombre, tnEdad, tnCosto
lnParams = PCOUNT()
Beneficios:
- LPARAMETERS crea parámetros Locales, o sea que se limpian automáticamente al terminar el método y los métodos que se llamen no verán las variables creadas, mientras que PARAMETERS los crea Privados y seguirán siendo visibles al llamar a otros métodos
- Creando los parámetros nuevos al final, se garantiza la compatibilidad de las llamadas existentes a este método sin necesidad de pruebas de regresión, porque de otra forma habría que cambiar todas las llamadas y volver a probar todo lo existente para verificar que no falle (pruebas de regresión)
- PCOUNT() lleva la cuenta de los parámetros del método actual, mientras que PARAMETERS() lleva la cuenta de los últimos parámetros recibidos en cuelquier método, incluyendo métodos externos al actual, lo que puede producir errores de evaluación
6. Uso de referencias de objeto
Recomendaciones:
- Definir siempre que sea posible las variables de objeto indicando la clase y librería de pertenencia
- Usar nombres significativos, que indiquen claramente para qué sirven
- Antes de liberar la referencia del objeto, asignarle NULL
- Liberar siempre las variables de objeto con RELEASE, y no confiar en la limpieza automática de Fox, porque a veces queda la referencia en memoria
- Usar variables de objeto en lugar de rutas de objetos tipo obj1.obj2.obj3.objN
- Si se deben usar muchas referencias de objetos en un bucle, usar WITH objeto .. ENDWITH
- Aunque no está documentado, en los parámetros definidos con "AS clase" para aprovechar Intellisense, no es conveniente referenciar clases de librerías o programas externas, sino solo clases nativas, ya que con las clases externas se puede provocar un error C0000005 fatal. Para referencias clases externas es mejor usar el truco del IF .F. descripto en el ejemplo de debajo, donde nunca se ejecutará su contenido, pero servirá para usar Intellisense.
Ejemplo 1: Referencia de objeto por parámetro
LPARAMETERS toEntorno, toException as Exception, tnCod as Integer
IF .F. && Truco para no ejecutar, pero poder definir Intellisense
LOCAL toEntorno AS "Entorno" OF "LIB_ENTORNO.PRG"
ENDIF
toEntorno.EspacioMinimoDeDisco = 100 && MB
Ejemplo 2: Uso de With..EndWith de forma óptima
WITH THISFORM.pgfConfig.pagEntrada.txtContador
FOR I = 1 TO 1000
.VALUE =.VALUE + 1
ENDFOR
ENDWITH
Ejemplo 3: Uso de Referencias de objeto cacheadas en variables
LOCAL loPagEntrada AS Page
loPagEntrada = THISFORM.pgfConfig.pagEntrada
loPagEntrada.txtUsuario.VALUE = ""
loPagEntrada.txtPassword.VALUE = ""
loPagEntrada.chkDiasVigencia.VALUE = 15
Beneficios:
- Definir las variables indicando la clase y la librería, permite usar Intellisense y acceder a la lista de miembros de la clase al poner el punto (objeto.<miembros>), lo que ahorra tiempo
- Usar nombres significativos facilita la compresión y claridad del código, y el mantenimiento futuro
- Asignar NULL a las referencias de objetos al terminar evita la referencias pendientes de tipo objeto, cuya acumulación puede provocar el error C0000005
- Liberar las variables de objeto con RELEASE es más rápido y seguro que el recolector de basura de Fox, donde a veces quedan colgadas en memoria
- Usar variables de objeto (ej: loPagEntrada) en vez de referencias de objeto largas (ej: thisform.pgfConfig.pagEntrada) permite ganar velocidad de ejecución por no requerir leer cada objeto de la secuencia, además permite mayor claridad en el código y ocupar bastante menos espacio, lo que hace que se pueda leer y entender más rápido
- Usar With..EndWith cuando hay muchas referencias de objeto o referencias dentro de un bucle FOR o DO WHILE siempre es lo más rápido, ya que el WITH cachea el objeto
7. Return
Recomendaciones:
- No usar RETURN en medio los métodos, sino sólo al final de los mismos, ya que si no se rompe el flujo natural del programa
- Jamás usar RETURN dentro de un ENDWITH! Deja referencias de objeto colgadas y al rato genera el error C0000005
- Agregar RETURN siempre al final de un método o procedimiento, para poder elegirlo durante una depuración y poder salir del método antes
Ejemplo:
LPARAMETERS tnValor
lnCodError = 0
IF tnValor <= 0
lnCodError = 1
ENDIF
RETURN lnCodError
Beneficios:
- Los RETURN al final del código permiten seguir el flujo del programa más fácilmente
- Se facilita la recolección de basura (liberación de tablas y variables, etc) en un único punto
- Es más fácil para depurar y permite saltearse todo el código e ir directo al Return para salir del método (a veces viene bien al depurar)
8. Manejo de Errores
El control de errores es fundamental en cualquier aplicación y no debe dejarse de lado o para el final, sino que debe formar parte del diseño. Este artículo te ayudará a entender cómo funciona el Try/Catch y cómo usarlo.
Recomendaciones:
- Controlar los errores en todos los puntos clave del sistema y no ignorarlos
- No dejar que FoxPro controles los errores con Abort-Retry-Ignore, porque es peligroso dejar esa decisión al usuario, ya que normalmente "ignorará" para seguir adelante
- Los errores se deben relanzar desde la capa de datos y negocio hacia la interfaz visual, donde se muestran
- Nunca deben mostrarse errores en una capa que no sea la Interfaz visual
Ejemplo:
TRY
lnCodError = 0
IF tnValor <= 0
lnCodError = 1
ENDIF
CATCH TO loEx
THROW
FINALLY
*-- Recolección de basura
ENDTRY
Beneficios:
- Try/Catch permite el manejo estructurado de errores, y relanzarlos o tratarlos localmente
- Finally permite recolectar la basura, tanto con o sin errores
- Relanzar los errores de negocio o de datos permite reutilizar esas lógicas, encapsularlas y testearlas de forma más fácil y aislada
- Al ser una estructura de control que envuelve al método, facilita el flujo del programa y permite salir de él con Exit, siempre por el final del método
- No permite usar RETURN dentro de la estructura (genera un error), lo que ayuda a estructurar y diseñar mejor el proceso
9. Separación en N capas y en funcionalidades (encapsulación)
Recomendaciones:
- Si se quiere usar la separación de 3 capas (datos, negocio e Interfaz), es importante no hacer los procesos en el form, sino en un proceso independiente que puede ser invocado desde el form, pero programado fuera de él. Quedan excluidos los procesos necesarios para gestionar la Interfaz, como rutinas de refresco y similares.
- Con los accesos a datos lo mismo: evitar usar sentencias DML (Data Manipulation Language, típicamente SQL) como Select, Update, Insert o Replace, dentro del form, y hacerlo fuera del form en procesos separados, por ejemplo las consultas de clientes o de artículos son casos típicos. Quedan excluidos los accesos a datos como necesidad del manejo de la pantalla, como cursores con metadatos usados para gestionar la Interfaz.
- Una misma librería no debería contener elementos de capas distintas (por ejemplo, forms, clases de negocio y clases de acceso a datos)
- Cada capa puede estar contenida en una o más librerías, dependiendo del diseño
- Evitar que los métodos o procedimientos hagan muchas cosas y preferir que hagan una sola cosa a la vez
- Si un método es muy largo o tiene muchos comentarios, es muy probable que haga varias cosas, lo que dificulta su mantenimiento, y sería mejor separarlo en métodos más chicos
- Los procesos complejos que requieren realizar varias tareas, conviene dividirlos de tal forma que haya un proceso central que solo gestione subprocesos (paso de datos entre ellos, gestión de errores, etc) mediante llamadas a los mismos, donde el subproceso es el único que implementa el código de la tarea necesaria
- Si se tienen las típicas hiper-librerías que lo hacen todo y que de tanta funcionalidad mezclada es son difíciles de mantener, una buena técnica de encapsulación, y muy simple, es reemplazar métodos con código por llamadas a métodos de librerías externas donde se mueva y adapte ese código. De esa forma se mantiene la API de la interfaz (los nombres de los métodos) pero se cargará mucho más rápido porque ya no contendrá todo el código inicial, sino solo las llamadas.
- Hay casos en los que es necesario rediseñar (cambiar la funcionalidad). No tener miedo de hacerlo, ya que puede ahorrar más tiempo que el que lleva mantener un código espagueti
Ejemplo 1: Código de una funcionalidad para externalizar
*-- Consultar artículo
(Aquí estaría todo el código que implementa la consulta, el control de errores, etc)
*-- Consultar artículo
(Aquí estaría todo el código que implementa la consulta, el control de errores, etc)
Ejemplo 1: Código externalizado como funcionalidad independiente
oBus.ConsultarArticulo(lcCodArt)
oBus.ConsultarArticulo(lcCodArt)
Ejemplo 2: Código de múltiples funcionalidades para externalizar
*-- Funcionalidad 1
(código con implementación de la funcionalidad 1)
*-- Funcionalidad 2
(código con implementación de la funcionalidad 2)
*-- Funcionalidad 3
(código con implementación de la funcionalidad 3)
*-- Funcionalidad 1
(código con implementación de la funcionalidad 1)
*-- Funcionalidad 2
(código con implementación de la funcionalidad 2)
*-- Funcionalidad 3
(código con implementación de la funcionalidad 3)
Ejemplo 2: Código externalizado como funcionalidades independientes
oBus.Funcionalidad_1()
oBus.Funcionalidad_2()
oBus.Funcionalidad_3()
oBus.Funcionalidad_1()
oBus.Funcionalidad_2()
oBus.Funcionalidad_3()
Beneficios:
- La separación en capas permite el mantenimiento por separado y granular de los distintos subsistemas
- Esta separación permite maximizar las posibilidades de reutilizar código en procesos desatendidos o para otros sistemas o relacionados al actual.
- La separación en librerías favorece su reutilización
- La separación en funcionalidades bien definidas que hacen una sola cosa en lo posible, no solo favorece la reutilización, sino también que facilita su testeo de forma separada al sistema mediante herramientas de Testing Unitario como FoxUnit
- La creación de métodos "Gestores" unido a una buena nomenclatura funcional, facilita el análisis, comprensión y mantenimiento del sistema, evitando tener que entrar en cada método para saber lo que hace
- En muchas ocasiones, el rediseño ahorra tiempo y mejora la calidad y mantenibilidad del código
10. Desarrollo sencillo y tonto (KISS)
Recomendaciones:
- Desarrollar con la simplicidad en mente
- Evitar complejidades innecesarias
- Si algo se complica, probablemente convenga separarlo en partes más simples o usar un método gestor de procesos
- Evitar los mega-procedimientos que hacen de todo, ya que suelen ser los más difíciles de arreglar si fallan, o de mantener, pasado un tiempo
- Usar nomenclatura clara que todos entiendan, y no "yo solo me entiendo", porque dentro de varios meses será "ni yo mismo me entiendo!"
- Cuando se modifica un código existente, siempre evaluar si hay algo mejorable o que pueda escribirse de forma más clara. Si se puede refactorizar, hacerlo en el momento; si se puede mejorar, pero es algo complejo o que llevará más tiempo, preparar una tarea posterior para "mantenimiento preventivo" y hacerla lo antes posible (futuro cercano, no lejano:)
- Usar los comentarios estrictamente necesarios, pero usarlos bien.
- Los comentarios deben explicar brevemente la funcionalidad no-obvia a primera vista, de otro modo, sobran y mejor no ponerlos
Ejemplo 1: Código para mejorar
If condición1
Else
If condición2
Else
If condición3
Else
EndIf
EndIf
EndIf
If condición1
Else
If condición2
Else
If condición3
Else
EndIf
EndIf
EndIf
Ejemplo 1: Código mejorado
Do Case
Case condición1
Case condición2
Case condición3
Otherwise
EndCase
Do Case
Case condición1
Case condición2
Case condición3
Otherwise
EndCase
Ejemplo 2: Comentario obvio
*-- Muestra un mensaje
MESSAGEBOX( "Este es un mensaje!" )
*-- Muestra un mensaje
MESSAGEBOX( "Este es un mensaje!" )
Ejemplo 2: Optimización
MESSAGEBOX( "Este es un mensaje!" )
MESSAGEBOX( "Este es un mensaje!" )
Ejemplo 3: Comentario obvio
*-- Si lActivateEjecutado=.F.
IF NOT lActivateEjecutado THEN
...(código)
*-- Si lActivateEjecutado=.F.
IF NOT lActivateEjecutado THEN
...(código)
Ejemplo 3: Comentario más útil
*-- Si no se ejecutó el evento activate
IF NOT lActivateEjecutado THEN
...(código)
*-- Si no se ejecutó el evento activate
IF NOT lActivateEjecutado THEN
...(código)
Beneficios:
- Cuanto más simple es un método, menos código tiene y más fácil de entender y mantener es
- Menos código implica menor probabilidad de errores
- Los nombres de métodos y variables que indican conceptos precisos y limitados, facilitan la legibilidad del código, su mantenimiento, su refactorización y su encapsulación
- Un código fácil de ver y mantener, implica un menor costo de mantenimiento
11. Desarrollar, Preparar Tests, Refactorizar y ejecutar Tests
Recomendaciones:
- Las tareas de un ciclo de desarrollo óptimo, sin un orden específico, son:
- Desarrollar la funcionalidad
- Crear tests automatizados (siempre que aporte beneficios)
- Refactorizar el código para simplificarlo lo más posible
- Ejecutar los tests antes creados para verificar que no se haya roto nada.
- El orden de estas tareas puede variar dependiento del paradigma de programación que se esté usando. Por ejemplo, si se usa TDD (Test Driven Development o Desarrollo Orientado por Tests), los Tests Unitarios automatizados es lo que se hace primero para generar lo que se conoce como "contrato", y luego se realiza el desarrollo para cubrir esa funcionalidad (y cumplir con el "contrato" funcional)
- La refactorización es parte de la tarea de desarrollo y no una mejora independiente para una etapa posterior o futura.
- Crear Tests Unitarios automatizados para cualquier funcionalidad o método donde el test aporte valor, por ejemplo, para métodos de cálculo, de evaluación de decisiones, de procesos y de cualquier funcionalidad, por pequeña que sea, cuyo mal funcionamiento pueda ser muy perjudicial para el sistema. No tiene sentido hacer Tests sobre cada método existente, porque hacerlos también conlleva un coste, y se debe buscar un equilibrio.
Beneficios:
- El hecho de realizar estas tareas de desarrollo (desarrollo, tests, refactorización) permite maximizar la calidad desde el principio
- La refactorización permite optimizar, depurar, limpiar y aclarar el código que se está escribiendo sin cambiar la funcionalidad, de cara a facilitar el mantenimiento del mismo
- Los Tests Unitarios automatizados permiten realizar comprobaciones automatizadas de procesos o funciones importantes para el sistema y además, como se mantienen en el tiempo, sirven como pruebas de regresión para las siguientes versiones, lo que implica un gran ahorro de tiempo de pruebas manuales
- Donde personalmente comprobé que TDD ahorra tiempo, es para la solución de incidencias, donde se sabe de antemano qué respuesta se esperaba de una función o proceso. En estos casos, se hacen primero los tests para reproducir el problema o error (sale el test en rojo), luego se hace la corrección del código y finalmente se vuelve a ejecutar el test, que ya debe salir en verde, lo que también permite comprobar que el test estaba bien hecho y que hace lo que debe.
12. Usabilidad
La usabilidad es la facilidad de poder usar un sistema.
Nota: Los efectos especiales que a algunos desarrolladores les gusta agregar a sus sistemas, a veces terminan haciendo que la usabilidad del mismo empeore, por lo que se debe tener cuidado en esto.
Recomendaciones:
- Permitir recorrer los controles con el teclado con un orden lógico y no caótico (normalmente con la tecla Tab o Enter), comenzando por arriba a la izquierda, e ir avanzando en sentido abajo-derecha
- Minimizar el uso de líneas y cajas 3D que tan de moda estuvieron con Windows 95 (1995)
- En el diseño de las pantallas, realizar agrupaciones y separaciones funcionales por medio de espaciado entre bloques, lo que sustituye a las líneas que antes se ponían por todos lados
- En vez de usar cajas (shapes, lines) para agrupar controles, intentar usar una línea de separación a modo de título y espacios a izquierda, derecha y debajo que separen del resto
- Alinear títulos y campos, tanto verticalmente como horizontalmente, y usar el mismo espaciado entre controles
- Usar siempre el mismo tipo de alineación de etiquetas: si se alinean a la izquierda, o a la derecha más cerca de los datos, hacerlo igual en todos los forms del sistema
- Todas las acciones que se lancen desde el form deben poder hacerse con un control claramente visible y pensado para tal acción (por ejemplo, un label no está pensado para eso, un botón de comando sí)
- Evitar el bloqueo de la navegación por la pantalla. Por ejemplo, no deberían mostrarse mensajes modales (tipo messagebox) por el solo hecho de recorrerla. La navegación debería ser libre.
- Intentar utilizar mecanismos no bloqueantes para mostrar mensajes al usuario. Por ejemplo, la línea de estado inferior, un espacio especial de notificación o una ventana que el usuario pueda invocar con una tecla o botón.
- Hacer un uso inteligente de los colores y las notificaciones gráficas, como iconos o mensajes. Por ejemplo, ante un error de ingreso por parte del usuario, se puede colorear el fondo de dicho control para que el usuario lo vea y de esta forma no lo bloquea
- Utilizar el control adecuado para el tipo de ingreso de datos o de selección requerido. Por ejemplo, no usar varios checkbox para simular on optingroup
- Diseñar dejando el espacio suficiente para los datos. El usuario debería poder ver el dato completo sin necesidad de hacer scroll dentro de un textbox demasiado pequeño, por ejemplo, o debería poder ver una opción seleccionada completa en un combobox sin necesidad de desplegarlo.
- En los cuandros de diálogo o pantallas de acción que requieran alguna decisión del usuario, poner siempre un botón para Cancelar o Salir, ya que algo como "Aceptar" solamente, no es una opción.
- Aprovechar la posibilidad de redimensionamiento de los forms y hacer buen uso de la propiedad Anchor, que permite redimensionar los controles
- Evitar los colores chillones y optar por colores tranquilos (hay guías sobre esto)
- Dado que hay sistemas en los que el usuario trabaja todo el día, el diseño y la usabilidad deben considerarse como algo muy importante, y evitar elementos que distraigan su atención
Ejemplos de diseño:
Ejemplo 1: Mal diseño
¿No sería mejor permitir Cancelar?
Un claro ejemplo de lo que podría ocurrir si no se permite:

Ejemplo 2: Mal diseño
Cajas y cajas y cajas dentro de cajas...

Ejemplo 3: Buen diseño
Este diseño que permite navegar sin bloquear al usuario con mensajes modales. Rápidamente se pueden ver los campos que tienen algún error (fondo rojo) y un mensaje en una zona especial indica el error ocurrido más inmediato. Además el botón Guardar no se habilita hasta que esté todo correcto, pero siempre se puede Salir y abandonar el proceso. Un botón extra podría permitir ver todos los errores de validación y posibles sugerencias de solución en un form aparte:

Ejemplo 4: Buen diseño
Observar a la derecha, un solo cuadro y 3 bloques de información separados por espacio, y un panel inferior separado por la sola presencia de los 4 botones de comando. Todo el conjunto usando tonos pastel entre vívidos y tranquilos, y muy amenos:
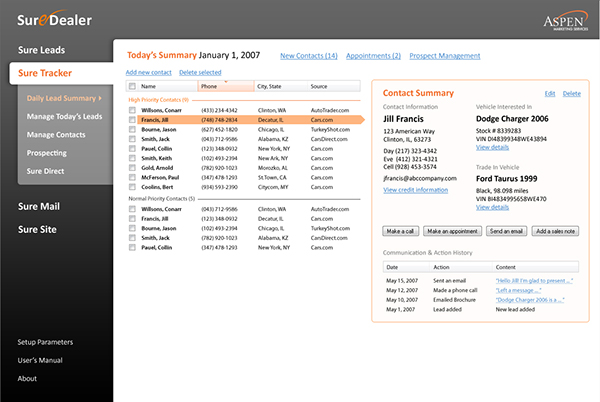
Beneficios:
- Un recorrido ordenado por la interfaz, permite predictibilidad
- Una interfaz clara minimiza los errores y aumenta la satisfacción del usuario
- Un buen diseño permite que el usuario pueda ser más eficiente, pueda hacer las tareas en menor tiempo y pueda distenderse
13. Usa Control de Versiones
[Artículo] ¿Para qué sirve? ¿Por qué es necesario?Nota final:
Esto no es todo, hay más, pero esta es una buena base para poder trabajar en un equipo o en solitario, ya que todas estas prácticas tienen como objetivo final el facilitar la comprensión y legibilidad del código, su encapsulación, también minimizar el costo de su mantenimiento y maximizar la satisfacción y eficiencia del usuario.
Hasta la próxima!





















